As database management became popular during the 1970s and 1980s, a handful of popular data models emerged. Each of these early data models had advantages and disadvantages that played key roles in the development of the relational data model. In many ways, the relational data model represented an attempt to streamline and simplify the earlier data models. To understand the role and contribution of SQL and the relational model, it is useful to briefly examine some data models that preceded the development of SQL.
1. File Management Systems
Before the introduction of database management systems, all data permanently stored on a computer system, such as payroll and accounting records, was stored in individual files. A file management system, usually provided by the computer manufacturer as part of the computer’s operating system, kept track of the names and locations of the files. The file management system basically had no data model; it knew nothing about the internal contents of files. To the file management system, a file containing a word processing document and a file containing payroll data appeared the same.
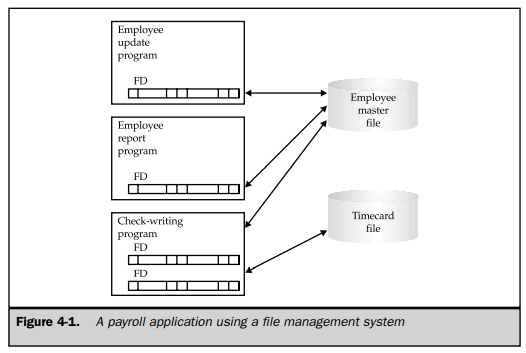
Knowledge about the contents of a file—which data it contained and how the data was organized—was embedded in the application programs that used the file, as shown in Figure 4-1. In this payroll application, each of the COBOL programs that processed the employee master file contained a file description (FD) that described the layout of the data in the file. If the structure of the data changed—for example, if an additional item of data was to be stored for each employee—every program that accessed the file had to be modified. As the number of files and programs grew over time, more and more of a data-processing department’s effort went into maintaining existing applications rather than developing new ones.
The problems of maintaining large file-based systems led in the late 1960s to the development of database management systems. The idea behind these systems was simple:
take the definition of a file’s content and structure out of the individual programs, and store it, together with the data, in a database. Using the information in the database, the DBMS that controlled it could take a much more active role in managing both the data and changes to the database structure.
2. Hierarchical Databases
One of the most important applications for the earliest database management systems was production planning for manufacturing companies. If an automobile manufacturer decided to produce 10,000 units of one car model and 5000 units of another model, it needed to know how many parts to order from its suppliers. To answer the question, the product (a car) had to be decomposed into assemblies (engine, body, chassis), which were decomposed into subassemblies (valves, cylinders, spark plugs), and then into sub-subassemblies, and so on. Handling this list of parts, known as a bill of materials, was a job tailor-made for computers.
The bill of materials for a product has a natural hierarchical structure. To store this data, the hierarchical data model, illustrated in Figure 4-2, was developed. In this model, each record in the database represented a specific part. The records had parent/child relationships, linking each part to its subpart, and so on.
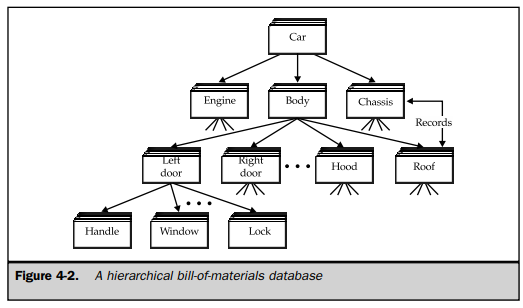
To access the data in the database, a program could perform the following tasks:
- Find a particular part by number (such as the left door)
- Move “down” to the first child (the door handle)
- Move “up” to its parent (the body)
- Move “sideways” to the next child (the right door)
Retrieving the data in a hierarchical database thus required navigating through the records, moving up, down, and sideways one record at a time.
One of the most popular hierarchical database management systems was IBM’s Information Management System (IMS), first introduced in 1968. The advantages of IMS and its hierarchical model follow.
- Simple structure. The organization of an IMS database was easy to understand. The database hierarchy paralleled that of a company organization chart or a family tree.
- Parent/child organization. An IMS database was excellent for representing parent/child relationships, such as “A is a part of B” or “A is owned by B.”
- Performance. IMS stored parent/child relationships as physical pointers from one data record to another, so that movement through the database was rapid. Because the structure was simple, IMS could place parent and child records close to one another on the disk, minimizing disk input/output.
IMS is still a very widely used DBMS on IBM mainframes. Its raw performance makes it the database of choice in high-volume transaction-processing applications such as processing bank ATM transactions, verifying credit card numbers, and tracking the delivery of overnight packages. Although relational database performance has improved dramatically over the last decade, the performance requirements of applications such as these have also increased, so IMS continues to have a role. In addition, the large amount of corporate data stored in IMS databases insures that IMS use will continue long after relational databases have eliminated the performance barrier.
3. Network Databases
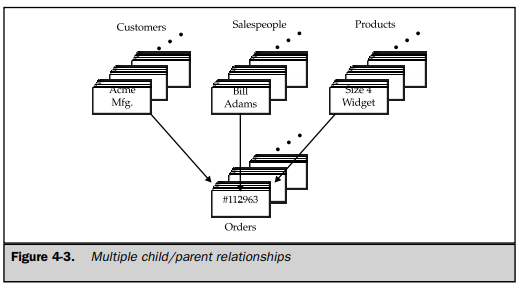
The simple structure of a hierarchical database became a disadvantage when the data had a more complex structure. In an order-processing database, for example, a single order might participate in three different parent/child relationships, linking the order to the customer who placed it, the salesperson who took it, and the product ordered, as shown in Figure 4-3. The structure of this type of data simply didn’t fit the strict hierarchy of IMS.
To deal with applications such as order processing, a new network data model was developed. The network data model extended the hierarchical model by allowing a record to participate in multiple parent/child relationships, as shown in Figure 4-4. These relationships were known as sets in the network model. In 1971, the Conference on Data Systems Languages published an official standard for network databases, which became known as the CODASYL model. IBM never developed a network DBMS of its own, choosing instead to extend IMS over the years. But during the 1970s, independent software companies rushed to embrace the network model, creating products such as Cullinet’s IDMS, Cincom’s Total, and the Adabas DBMS that became very popular.
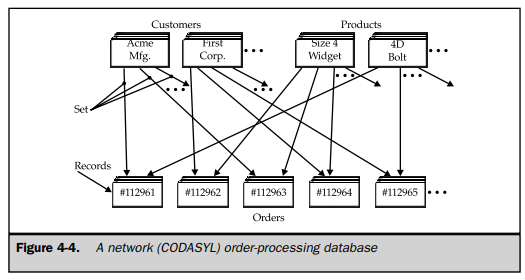
For a programmer, accessing a network database was very similar to accessing a hierarchical database. An application program could do the following:
- Find a specific parent record by key (such as a customer number)
- Move down to the first child in a particular set (the first order placed by this customer)
- Move sideways from one child to the next in the set (the next order placed by the same customer)
- Move up from a child to its parent in another set (the salesperson who took the order)
Once again, the programmer had to navigate the database record by record, this time specifying which relationship to navigate as well as the direction.
Network databases had several advantages:
- Flexibility. Multiple parent/child relationships allowed a network database to represent data that did not have a simple hierarchical structure.
- Standardization. The CODASYL standard boosted the popularity of the network model, and minicomputer vendors such as Digital Equipment Corporation and Data General implemented network databases.
- Performance. Despite their greater complexity, network databases boasted performance approaching that of hierarchical databases. Sets were represented by pointers to physical data records, and on some systems, the database administrator could specify data clustering based on a set relationship.
Network databases had their disadvantages, too. Like hierarchical databases, they were very rigid. The set relationships and the structure of the records had to be specified in advance. Changing the database structure typically required rebuilding the entire database.
Both hierarchical and network databases were tools for programmers. To answer a question such as “What is the most popular product ordered by Acme Manufacturing?” a programmer had to write a program that navigated its way through the database.
The backlog of requests for custom reports often stretched to weeks or months, and by the time the program was written, the information it delivered was often worthless.
The disadvantages of the hierarchical and network models led to intense interest in the new relational data model when it was first described by Dr. Codd in 1970. At first the relational model was little more than an academic curiosity. Network databases continued to be important throughout the 1970s and early 1980s, particularly on the minicomputer systems that were surging in popularity. However, by the mid-1980s, the relational model was clearly emerging as the “new wave” in data management. By the early 1990s, network databases were clearly declining in importance, and today they no longer play a major role in the database market.
Source: Liang Y. Daniel (2013), Introduction to programming with SQL, Pearson; 3rd edition.