THIS CHAPTER DESCRIBES SOME FUNDAMENTAL TERMS that you must understand before you can learn how to program in C. A general overview of the nature of programming in a higher-level language is provided, as is a discussion of the process of compiling a program developed in such a language.
1. Programming
Computers are really very dumb machines indeed because they do only what they are told to do. Most computer systems perform their operations on a very primitive level. For example, most computers know how to add one to a number or how to test whether a number is equal to zero. The sophistication of these basic operations usually does not go much further than that. The basic operations of a computer system form what is known as the computer’s instruction set.
To solve a problem using a computer, you must express the solution to the problem in terms of the instructions of the particular computer. A computer program is just a col- lection of the instructions necessary to solve a specific problem. The approach or method that is used to solve the problem is known as an algorithm. For example, if you want to develop a program that tests if a number is odd or even, the set of statements that solves the problem becomes the program. The method that is used to test if the number is even or odd is the algorithm. Normally, to develop a program to solve a particular problem, you first express the solution to the problem in terms of an algorithm and then develop
a program that implements that algorithm. So, the algorithm for solving the even/odd problem might be expressed as follows: First, divide the number by two. If the remainder of the division is zero, the number is even; otherwise, the number is odd. With the algo- rithm in hand, you can then proceed to write the instructions necessary to implement the algorithm on a particular computer system. These instructions would be expressed in the statements of a particular computer language, such as Visual Basic, Java, C++, or C.
2. Higher-Level Languages
When computers were first developed, the only way they could be programmed was in terms of binary numbers that corresponded directly to specific machine instructions and locations in the computer’s memory. The next technological software advance occurred in the development of assembly languages, which enabled the programmer to work with the machine on a slightly higher level. Instead of having to specify sequences of binary numbers to carry out particular tasks, the assembly language permits the programmer to use symbolic names to perform various operations and to refer to specific memory loca- tions. A special program, known as an assembler, translates the assembly language program from its symbolic format into the specific machine instructions of the computer system.
Because a one-to-one correspondence still exists between each assembly language statement and a specific machine instruction, assembly languages are regarded as low- level languages. The programmer must still learn the instruction set of the particular computer system to write a program in assembly language, and the resulting program is not portable; that is, the program will not run on a different processor type without being rewritten. This is because different processor types have different instruction sets, and because assembly language programs are written in terms of these instruction sets, they are machine dependent.
Then, along came the so-called higher-level languages, of which the FORTRAN (FORmula TRANslation) language was one of the first. Programmers developing pro- grams in FORTRAN no longer had to concern themselves with the architecture of the particular computer, and operations performed in FORTRAN were of a much more sophisticated or higher level, far removed from the instruction set of the particular machine. One FORTRAN instruction or statement resulted in many different machine instructions being executed, unlike the one-to-one correspondence found between assembly language statements and machine instructions.
Standardization of the syntax of a higher-level language meant that a program could be written in the language to be machine independent. That is, a program could run on any machine that supported the language with few or no changes.
To support a higher-level language, a special computer program must be developed that translates the statements of the program developed in the higher-level language into a form that the computer can understand—in other words, into the particular instruc- tions of the computer. Such a program is known as a compiler.
3. Operating Systems
Before continuing with compilers, it is worthwhile to understand the role that is played by a computer program known as an operating system.
An operating system is a program that controls the entire operation of a computer system. All input and output (that is, I/O) operations that are performed on a computer system are channeled through the operating system. The operating system must also manage the computer system’s resources and must handle the execution of programs.
One of the most popular operating systems today is the Unix operating system, which was developed at Bell Laboratories. Unix is a rather unique operating system in that it can be found on many different types of computer systems, and in different “flavors,” such as Linux or Mac OS X. Historically, operating systems were typically asso- ciated with only one type of computer system. But because Unix was written primarily in the C language and made very few assumptions about the architecture of the comput- er, it has been successfully ported to many different computer systems with a relatively small amount of effort.
Microsoft Windows XP is another example of a popular operating system. That sys- tem is found running primarily on Pentium (or Pentium-compatible) processors.
4. Compiling Programs
A compiler is a software program that is, in principle, no different than the ones you will see in this book, although it is certainly much more complex. A compiler analyzes a pro- gram developed in a particular computer language and then translates it into a form that is suitable for execution on your particular computer system.
Figure 2.1 shows the steps that are involved in entering, compiling, and executing a computer program developed in the C programming language and the typical Unix commands that would be entered from the command line.
The program that is to be compiled is first typed into a file on the computer system. Computer installations have various conventions that are used for naming files, but in general, the choice of the name is up to you. C programs can typically be given any name provided the last two characters are “.c” (this is not so much a requirement as it is a convention). So, the name prog1.c might be a valid filename for a C program on your system.
A text editor is usually used to enter the C program into a file. For example, vi is a popular text editor used on Unix systems. The program that is entered into the file is known as the source program because it represents the original form of the program expressed in the C language. After the source program has been entered into a file, you can then proceed to have it compiled.
The compilation process is initiated by typing a special command on the system. When this command is entered, the name of the file that contains the source program must also be specified. For example, under Unix, the command to initiate program com- pilation is called cc. If you are using the popular GNU C compiler, the command you use is gcc. Typing the line
gcc prog1.c
has the effect of initiating the compilation process with the source program contained in
prog1.c.
In the first step of the compilation process, the compiler examines each program statement contained in the source program and checks it to ensure that it conforms to the syntax and semantics of the language1. If any mistakes are discovered by the compiler during this phase, they are reported to the user and the compilation process ends right there. The errors then have to be corrected in the source program (with the use of an editor), and the compilation process must be restarted. Typical errors reported during this phase of compilation might be due to an expression that has unbalanced parentheses (syntactic error), or due to the use of a variable that is not “defined” (semantic error).
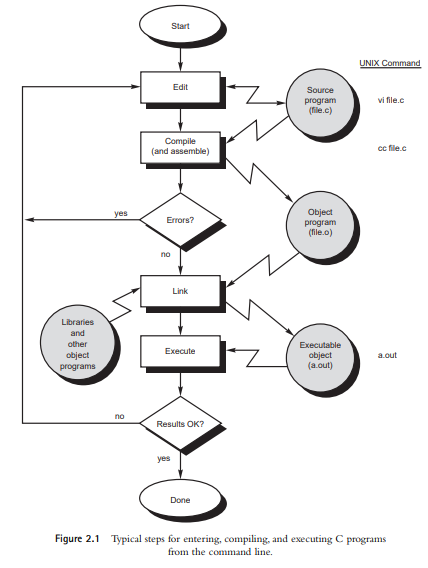
When all the syntactic and semantic errors have been removed from the program, the compiler then proceeds to take each statement of the program and translate it into a “lower” form. On most systems, this means that each statement is translated by the com- piler into the equivalent statement or statements in assembly language needed to per- form the identical task.
After the program has been translated into an equivalent assembly language program, the next step in the compilation process is to translate the assembly language statements into actual machine instructions. This step might or might not involve the execution of a separate program known as an assembler. On most systems, the assembler is executed automatically as part of the compilation process.
The assembler takes each assembly language statement and converts it into a binary format known as object code, which is then written into another file on the system. This file typically has the same name as the source file under Unix, with the last letter an “o” (for object) instead of a “c”. Under Windows, the suffix letters “obj” typically replace the “c” in the filename.
After the program has been translated into object code, it is ready to be linked. This process is once again performed automatically whenever the cc or gcc command is issued under Unix. The purpose of the linking phase is to get the program into a final form for execution on the computer. If the program uses other programs that were pre- viously processed by the compiler, then during this phase the programs are linked together. Programs that are used from the system’s program library are also searched and linked together with the object program during this phase.
The process of compiling and linking a program is often called building.
The final linked file, which is in an executable object code format, is stored in another file on the system, ready to be run or executed. Under Unix, this file is called a.out by default. Under Windows, the executable file usually has the same name as the source file, with the c extension replaced by an exe extension.
To subsequently execute the program, all you do is type in the name of the exe-cutable object file. So, the command
a.out
has the effect of loading the program called a.out into the computer’s memory and initi- ating its execution.
When the program is executed, each of the statements of the program is sequentially executed in turn. If the program requests any data from the user, known as input, the program temporarily suspends its execution so that the input can be entered. Or, the program might simply wait for an event, such as a mouse being clicked, to occur. Results that are displayed by the program, known as output, appear in a window, sometimes called the console. Or, the output might be directly written to a file on the system.
If all goes well (and it probably won’t the first time the program is executed), the pro- gram performs its intended functions. If the program does not produce the desired
results, it is necessary to go back and reanalyze the program’s logic. This is known as the debugging phase, during which an attempt is made to remove all the known problems or bugs from the program. To do this, it will most likely be necessary to make changes to the original source program. In that case, the entire process of compiling, linking, and executing the program must be repeated until the desired results are obtained.
5. Integrated Development Environments
The individual steps involved in developing C programs were outlined earlier, showing typical commands that would be entered for each step. This process of editing, compil- ing, running, and debugging programs is often managed by a single integrated applica- tion known as an Integrated Development Environment, or IDE for short. An IDE is a windows-based program that allows you to easily manage large software programs, edit files in windows, and compile, link, run, and debug your programs.
On Mac OS X, CodeWarrior and Xcode are two IDEs that are used by many pro- grammers. Under Windows, Microsoft Visual Studio is a good example of a popular IDE. Kylix is a popular IDE for developing applications under Linux. All the IDE applications greatly simplify the entire process involved in program development so it is worth your while to learn how to use one. Most IDEs also support program development in several different programming languages in addition to C, such as C# and C++.
For more information about IDEs, consult Appendix E, “Resources.”
6. Language Interpreters
Before leaving this discussion of the compilation process, note that there is another method used for analyzing and executing programs developed in a higher-level language. With this method, programs are not compiled but are interpreted. An interpreter analyzes and executes the statements of a program at the same time. This method usually allows programs to be more easily debugged. On the other hand, interpreted languages are typi- cally slower than their compiled counterparts because the program statements are not converted into their lowest-level form in advance of their execution.
BASIC and Java are two programming languages in which programs are often inter- preted and not compiled. Other examples include the Unix system’s shell and Python. Some vendors also offer interpreters for the C programming language.
Source: Kochan Stephen G. (2020), Programming in C: A Complete Introduction to the C Programming Language, Sams; Subsequent edition.