1. Introduction
It is useful to know a little about the technical aspects of the Internet and the Web in order to better understand the various terminologies used in this book and also how what you produce will generally work. If you find that something is too technical in this chapter, you can skip it and then come back to it when you feel more comfortable with the subject or feel the need to know it.
2. Fundamentals of the Internet and the Web
The Internet is the technological framework on which the Web, also known as World Wide Web (WWW), runs. It is a global network of interconnected computer networks that comprises millions of different types of networks, such as home, private, academic, business, public, and government networks, linked through various types of connection technologies, such as fiber optic cable and wireless. The Web is only one of the applications that the Internet supports. Other applications include email, telephony, and file sharing.
Central to how computers or devices on the Internet communicate with each other and send data around are the relationship between them and the system they use to communicate with each other. There are broadly two models of relationship: client-server model and peer-to-peer model. In the client-server network model, one computer is the server and the others are clients. The clients request data from the server and the server provides the data to clients. In contrast, a peer-to-peer network is one in which all computers have equal responsibilities; that is, every computer in the network works as both a server and a client. In essence, the snippets of a single file are distributed across the computers of multiple users, so that when there is a request for the file, it is compiled from these sources. This is the model that file-sharing services, such as Freenet, typically use.
In order for the computers on the Internet to communicate successfully, the Internet uses a suite of protocols, the most important of which, as of time of writing, are Transfer Control Protocol (TCP) and Internet Protocol (IP). IP is used for transmitting packets of data from one computer to another, using the computers’ unique addresses, and TCP is used to verify the accuracy of the data being transmitted. Internet protocol suite is often generally referred to as TCP/IP.
The unique address of a computer on the Internet, or indeed any network, is known as IP address, and it is the unique number that makes it possible to identify a computer on the Internet. The original IP address format, known as IPv4, is a four-part number written, for example, as 208.132.59.234. However, the enormous growth of the Internet has led to the introduction of IPv6, which is a six-part number. To make an IP address easy to remember, it is normally associated with a name, called domain name, for example, bbc.co.uk. Like any protocol, Internet protocols impose rule and order on how things are done. Basically, they specify rules and encoding specifications for sending data from one computer to another. Without these protocols, it would be impossible for so many computers to communicate successfully at the same time. It would be like having no queues at a crowded supermarket.
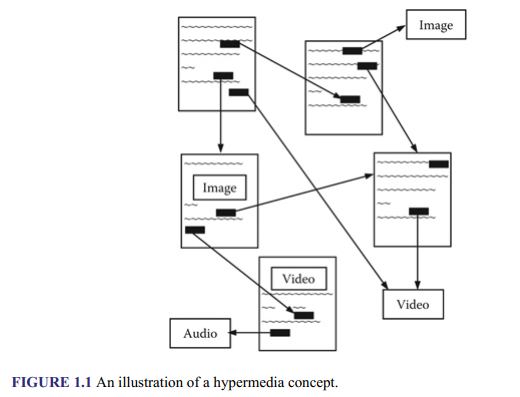
In contrast to the Internet, the Web is a system that enables files on various servers to be linked to each other. This is made possible through a technology known as hypertext, invented by Ted Nelson. The term refers to both the technology and the principle that enables the linking of a text element to another on a computer. It makes it possible to construct a dynamic information network by using hyperlinks, so that when a text is clicked, for example, with a mouse, it leads a user to another textual piece of information. When different types of media objects, such as text, images, sound, and video, are linked together instead of just text, the concept is referred to as hypermedia. Figure 1.1 shows an illustration of a basic hypermedia system. It shows documents containing hyperlinks to other documents and media objects. The documents and media objects could be on the same Web server or on different ones that are miles apart.
A hypermedia system can be made to behave in different ways. For example, clicking a hyperlink could open a document or a media file to which it is linked; and the document and media could both be on one computer or on separate computers located far apart. These computers are known as Web servers. They are powerful computers that run special programs and are permanently connected to the Internet. Although, in theory, people can have their website on their own Web server at home, it is usually not practical for various reasons, such as cost. Therefore, only big companies usually have their own Web servers. For everyone else, it is more practical to use Web hosting services. These are companies that own and maintain big powerful Web servers and charge a fee to host people’s websites on them. For mere surfing of the Web, no more than an Internet service provider (IPS) is required. An Internet service provider essentially connects you to the Internet; however, some also provide Web hosting.
The files on Web servers are usually accessed using a Web browser (technically known as Web client). Popular Web browsers include Internet Explorer, Microsoft Edge, Firefox, Chrome, Safari, and Opera. Technologies, such as Web browsers, that render files into Web pages in one form or another are generally referred to as user agents. For each file or document (i.e., resource) on a Web server, there is a unique address, known as Uniform Resource Locator (URL) or Web address, which describes its location. You may also come across the terms URI and URN. The relationship between these terms is clarified further shortly in the NOTE box. The format of a URL is as follows:
URL = protocol + IP address of server + location of file on server
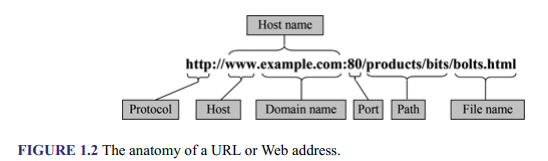
The syntax is: protocol://host.domain [:port]/path/filename Therefore, the URL for a file situated on a Web server on the Internet might be written as shown in Figure 1.2.
In the example, the name of the file is “bolts.html” It is located in the “bits” folder (or directory), which itself is in the “products” folder on a server called “example.com,” which is a WWW server (i.e., a Web server). HyperText Transfer Protocol (HTTP) is the protocol used by the Web for data communication, and 80 is the port that the browser typically uses to establish connection with a Web server, and assumed, so it is normally omitted when an address is specified. In order to access a file on a Web server, a user would typically enter the Web address in a Web browser, click a link to it on a Web page that is already opened, or choose it from the bookmark, which is a list of previously stored visited Web addresses.
How the browser delivers a requested file depends on the type of file. If it is a Web page, it is automatically displayed as a Web page, but if it is another type of file, such as a Word document, you may be given various other options, such as the option to save or open it. For files that are not Web pages, the browser may use other types of software, which are categorized as plug-ins and helper applications. A plug-in is embedded within a Web page, while a helper application is separate from the browser and operates independently of it, once the browser initiates it. Different types of files require different types of plug-ins or helper applications.
Although the Web is still most commonly accessed via desktop and laptop computers as of time of writing, it is increasingly accessed via a wide range of mobile devices, such as tablets and mobile phones, the capabilities and screen sizes of which vary widely. In addition, the Web is accessed by a wide range of people, including those with disabilities. The implication of this is that in order to reach as many people as possible, a website needs to be created in a way that allows viewing on a variety of devices and supports assistive technologies, which are the technologies that people with disabilities use to access Web pages. A common example is the screen reader, used by blind and visually impaired people to read out the contents of a Web page. Indeed, in many countries, some types of websites are required by law to be accessible to those with disabilities.
3. How the Web Works
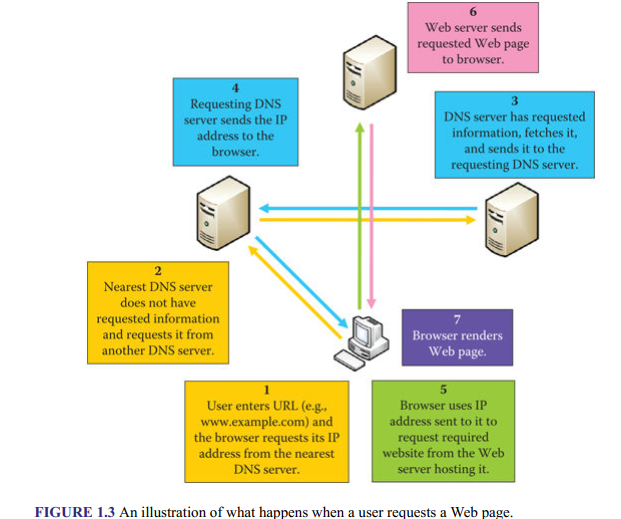
When a user that is connected to the Internet types a website address in the browser or clicks on a link to the address, in order for the browser to know the location (i.e., IP address) of the Web server hosting the site and so be able to connect to it and request the site, it connects to the nearest Domain Name System (DNS) server to request the IP address. A DNS server (or name server) is a computer that manages a huge database that stores and maps domain names (Web addresses) to IP addresses, and there are many such servers located all over the world on every continent. They are basically like phonebooks. If the DNS server does not have the requested IP address, it requests it from another DNS server, which requests it from yet another one if it too does not have it, and so on, until options run out. If the IP address is found, it is sent to the browser. The browser uses it to connect to the Web server that hosts the required website and requests it. The Web server sends it and the browser displays it. Figure 1.3 shows an illustration.
4. Requirements for Creating Websites
Different types of websites require different levels of complexity in their creation, and level of complexity determines the range of languages necessary. Some languages are easy to learn and use, while others are relatively difficult. Most websites use HyperText Markup Language (HTML) and Cascading Style Sheets (CSS), because they are responsible for the look and feel of a page. In the case of static websites (i.e., websites in which content is not generated dynamically, such as personal websites), these two technologies are usually all that is required.
For dynamic websites containing a lot of interaction, it is usually necessary to use an additional technology known as JavaScript, which is a programming language that is typically run on the browser side. For more complex dynamic websites that require the storing and retrieval of users’ data, such as e-commerce and dating sites, the use of a database is necessary, and so is the use of programming, to help the Web server carry out complex decision-making processes at the backend. Typically used programming languages include PHP, ASP.Net, Java, and Ruby. Of course, these languages in the end are still used to generate HTML and CSS, which the browser then uses to structure and style what it displayed on the screen. Most Web development authoring tools, which are graphical user interface (GUI) tools, allow you to use all these languages. An example is Dreamweaver.
For the types of websites that are updated regularly but do not necessarily involve a lot of interaction, programming is typically not required. They are often built using tools such as Web content management systems (WCMSs), e-commerce software, and blogging tools. These tools allow the creation of websites through simply selecting design templates and options for various pre-defined functionalities. Again, what they output and send to the browser are HTML and CSS.
Source: Sklar David (2016), HTML: A Gentle Introduction to the Web’s Most Popular Language, O’Reilly Media; 1st edition.